Kafka
Creating a data generator for Kafka. You will build a Docker image that will be able to populate data in kafka for the topics you configure.
Requirements
- 10 minutes
- Git
- Gradle
- Docker
- Kafka
Get Started
First, we will clone the data-caterer-example repo which will already have the base project setup required.
git clone git@github.com:data-catering/data-caterer-example.git
git clone git@github.com:data-catering/data-caterer-example.git
git clone git@github.com:data-catering/data-caterer-example.git
If you already have a Kafka instance running, you can skip to this step.
Kafka Setup
Next, let's make sure you have an instance of Kafka up and running in your local environment. This will make it easy for us to iterate and check our changes.
cd docker
docker-compose up -d kafka
Plan Setup
Create a new Java or Scala class.
- Java:
src/main/java/io/github/datacatering/plan/MyAdvancedKafkaJavaPlan.java - Scala:
src/main/scala/io/github/datacatering/plan/MyAdvancedKafkaPlan.scala
Make sure your class extends PlanRun.
import io.github.datacatering.datacaterer.java.api.PlanRun;
public class MyAdvancedKafkaJavaPlan extends PlanRun {
}
import io.github.datacatering.datacaterer.api.PlanRun
class MyAdvancedKafkaPlan extends PlanRun {
}
This class defines where we need to define all of our configurations for generating data. There are helper variables and methods defined to make it simple and easy to use.
Connection Configuration
Within our class, we can start by defining the connection properties to connect to Kafka.
var accountTask = kafka(
"my_kafka", //name
"localhost:9092", //url
Map.of() //optional additional connection options
);
Additional options can be found here.
val accountTask = kafka(
"my_kafka", //name
"localhost:9092", //url
Map() //optional additional connection options
)
Additional options can be found here.
Schema
Let's create a task for inserting data into the account-topic that is already
defined underdocker/data/kafka/setup_kafka.sh. This topic should already be setup for you if you followed this
step. We can check if the topic is set up already via the following command:
docker exec docker-kafkaserver-1 kafka-topics --bootstrap-server localhost:9092 --list
Trimming the connection details to work with the docker-compose Kafka, we have a base Kafka connection to define
the topic we will publish to. Let's define each field along with their corresponding data type. You will notice that
the text fields do not have a data type defined. This is because the default data type is StringType.
{
var kafkaTask = kafka("my_kafka", "kafkaserver:29092")
.topic("account-topic")
.schema(
field().name("key").sql("content.account_id"),
field().name("value").sql("TO_JSON(content)"),
//field().name("partition").type(IntegerType.instance()), can define partition here
field().name("headers")
.type(ArrayType.instance())
.sql(
"ARRAY(" +
"NAMED_STRUCT('key', 'account-id', 'value', TO_BINARY(content.account_id, 'utf-8'))," +
"NAMED_STRUCT('key', 'updated', 'value', TO_BINARY(content.details.updated_by.time, 'utf-8'))" +
")"
),
field().name("content")
.schema(
field().name("account_id").regex("ACC[0-9]{8}"),
field().name("year").type(IntegerType.instance()),
field().name("amount").type(DoubleType.instance()),
field().name("details")
.schema(
field().name("name").expression("#{Name.name}"),
field().name("first_txn_date").type(DateType.instance()).sql("ELEMENT_AT(SORT_ARRAY(content.transactions.txn_date), 1)"),
field().name("updated_by")
.schema(
field().name("user"),
field().name("time").type(TimestampType.instance())
)
),
field().name("transactions").type(ArrayType.instance())
.schema(
field().name("txn_date").type(DateType.instance()).min(Date.valueOf("2021-01-01")).max("2021-12-31"),
field().name("amount").type(DoubleType.instance())
)
),
field().name("tmp_year").sql("content.year").omit(true),
field().name("tmp_name").sql("content.details.name").omit(true)
)
}
val kafkaTask = kafka("my_kafka", "kafkaserver:29092")
.topic("account-topic")
.schema(
field.name("key").sql("content.account_id"),
field.name("value").sql("TO_JSON(content)"),
//field.name("partition").type(IntegerType), can define partition here
field.name("headers")
.`type`(ArrayType)
.sql(
"""ARRAY(
| NAMED_STRUCT('key', 'account-id', 'value', TO_BINARY(content.account_id, 'utf-8')),
| NAMED_STRUCT('key', 'updated', 'value', TO_BINARY(content.details.updated_by.time, 'utf-8'))
|)""".stripMargin
),
field.name("content")
.schema(
field.name("account_id").regex("ACC[0-9]{8}"),
field.name("year").`type`(IntegerType).min(2021).max(2023),
field.name("amount").`type`(DoubleType),
field.name("details")
.schema(
field.name("name").expression("#{Name.name}"),
field.name("first_txn_date").`type`(DateType).sql("ELEMENT_AT(SORT_ARRAY(content.transactions.txn_date), 1)"),
field.name("updated_by")
.schema(
field.name("user"),
field.name("time").`type`(TimestampType),
),
),
field.name("transactions").`type`(ArrayType)
.schema(
field.name("txn_date").`type`(DateType).min(Date.valueOf("2021-01-01")).max("2021-12-31"),
field.name("amount").`type`(DoubleType),
)
),
field.name("tmp_year").sql("content.year").omit(true),
field.name("tmp_name").sql("content.details.name").omit(true)
)
Fields
The schema defined for Kafka has a format that needs to be followed as noted above. Specifically, the required fields are: - value
Whilst, the other fields are optional:
- key
- partition
- headers
headers
headers follows a particular pattern that where it is of type array<struct<key: string,value: binary>>. To be able
to generate data for this data type, we need to use an SQL expression like the one below. You will notice that in the
value part, it refers to content.account_id where content is another field defined at the top level of the schema.
This allows you to reference other values that have already been generated.
field().name("headers")
.type(ArrayType.instance())
.sql(
"ARRAY(" +
"NAMED_STRUCT('key', 'account-id', 'value', TO_BINARY(content.account_id, 'utf-8'))," +
"NAMED_STRUCT('key', 'updated', 'value', TO_BINARY(content.details.updated_by.time, 'utf-8'))" +
")"
)
field.name("headers")
.`type`(ArrayType)
.sql(
"""ARRAY(
| NAMED_STRUCT('key', 'account-id', 'value', TO_BINARY(content.account_id, 'utf-8')),
| NAMED_STRUCT('key', 'updated', 'value', TO_BINARY(content.details.updated_by.time, 'utf-8'))
|)""".stripMargin
)
transactions
transactions is an array that contains an inner structure of txn_date and amount. The size of the array generated
can be controlled via arrayMinLength and arrayMaxLength.
field().name("transactions").type(ArrayType.instance())
.schema(
field().name("txn_date").type(DateType.instance()).min(Date.valueOf("2021-01-01")).max("2021-12-31"),
field().name("amount").type(DoubleType.instance())
)
field.name("transactions").`type`(ArrayType)
.schema(
field.name("txn_date").`type`(DateType).min(Date.valueOf("2021-01-01")).max("2021-12-31"),
field.name("amount").`type`(DoubleType),
)
details
details is another example of a nested schema structure where it also has a nested structure itself in updated_by.
One thing to note here is the first_txn_date field has a reference to the content.transactions array where it will
sort the array by txn_date and get the first element.
field().name("details")
.schema(
field().name("name").expression("#{Name.name}"),
field().name("first_txn_date").type(DateType.instance()).sql("ELEMENT_AT(SORT_ARRAY(content.transactions.txn_date), 1)"),
field().name("updated_by")
.schema(
field().name("user"),
field().name("time").type(TimestampType.instance())
)
)
field.name("details")
.schema(
field.name("name").expression("#{Name.name}"),
field.name("first_txn_date").`type`(DateType).sql("ELEMENT_AT(SORT_ARRAY(content.transactions.txn_date), 1)"),
field.name("updated_by")
.schema(
field.name("user"),
field.name("time").`type`(TimestampType),
),
)
Additional Configurations
At the end of data generation, a report gets generated that summarises the actions it performed. We can control the output folder of that report via configurations.
var config = configuration()
.generatedReportsFolderPath("/opt/app/data/report");
val config = configuration
.generatedReportsFolderPath("/opt/app/data/report")
Execute
To tell Data Caterer that we want to run with the configurations along with the kafkaTask, we have to call execute
.
Run
Now we can run via the script ./run.sh that is in the top level directory of the data-caterer-example to run the class we just
created.
./run.sh
#input class AdvancedKafkaJavaPlanRun or AdvancedKafkaPlanRun
#after completing
docker exec docker-kafkaserver-1 kafka-console-consumer --bootstrap-server localhost:9092 --topic account-topic --from-beginning
Your output should look like this.
{"account_id":"ACC56292178","year":2022,"amount":18338.627721151555,"details":{"name":"Isaias Reilly","first_txn_date":"2021-01-22","updated_by":{"user":"FgYXbKDWdhHVc3","time":"2022-12-30T13:49:07.309Z"}},"transactions":[{"txn_date":"2021-01-22","amount":30556.52125487579},{"txn_date":"2021-10-29","amount":39372.302259554635},{"txn_date":"2021-10-29","amount":61887.31389495968}]}
{"account_id":"ACC37729457","year":2022,"amount":96885.31758764731,"details":{"name":"Randell Witting","first_txn_date":"2021-06-30","updated_by":{"user":"HCKYEBHN8AJ3TB","time":"2022-12-02T02:05:01.144Z"}},"transactions":[{"txn_date":"2021-06-30","amount":98042.09647765031},{"txn_date":"2021-10-06","amount":41191.43564742036},{"txn_date":"2021-11-16","amount":78852.08184809204},{"txn_date":"2021-10-09","amount":13747.157653571106}]}
{"account_id":"ACC23127317","year":2023,"amount":81164.49304198896,"details":{"name":"Jed Wisozk","updated_by":{"user":"9MBFZZ","time":"2023-07-12T05:56:52.397Z"}},"transactions":[]}
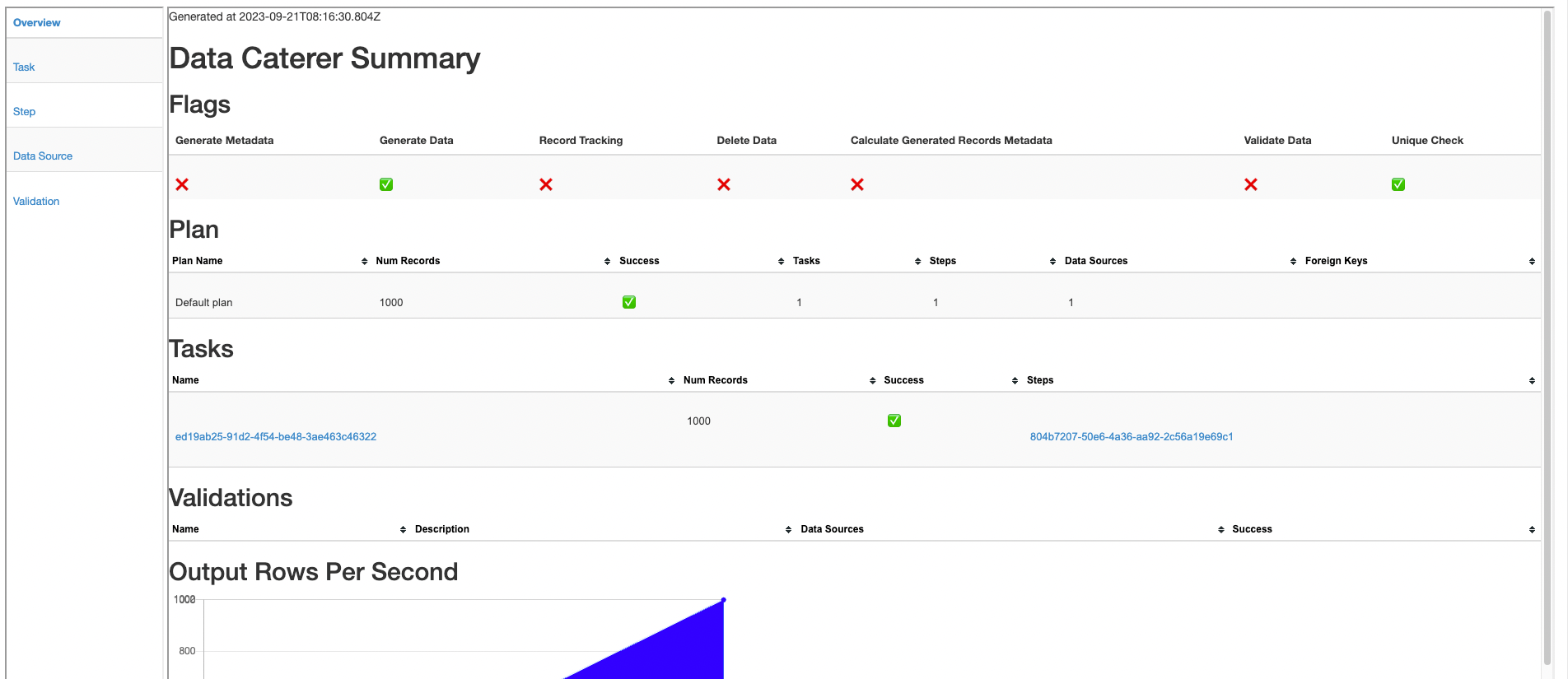
Also check the HTML report, found at docker/sample/report/index.html, that gets generated to get an overview of what
was executed.